Improve Local LLM Performance with Dedicated Task Models
Improve Performance with Dedicated Task Models
Open-WebUI provides several automated features—such as title generation, tag creation, autocomplete, and search query generation—to enhance the user experience. However, these features can generate multiple simultaneous requests to your local model, which may impact performance on systems with limited resources.
This guide explains how to optimize your setup by configuring a dedicated, lightweight task model or by selectively disabling automation features, ensuring that your primary chat functionality remains responsive and efficient.
Why Does Open-WebUI Feel Slow?
By default, Open-WebUI has several background tasks that can make it feel like magic but can also place a heavy load on local resources:
- Title Generation
- Tag Generation
- Autocomplete Generation (this function triggers on every keystroke)
- Search Query Generation
Each of these features makes asynchronous requests to your model. For example, continuous calls from the autocomplete feature can significantly delay responses on devices with limited memory or processing power, such as a Mac with 32GB of RAM running a 32B quantized model.
Optimizing the task model can help isolate these background tasks from your main chat application, improving overall responsiveness.
⚡ How to Optimize Task Model Performance
Follow these steps to configure an efficient task model:
Step 1: Access the Admin Panel
- Open Open-WebUI in your browser.
- Navigate to the Admin Panel.
- Click on Settings in the sidebar.
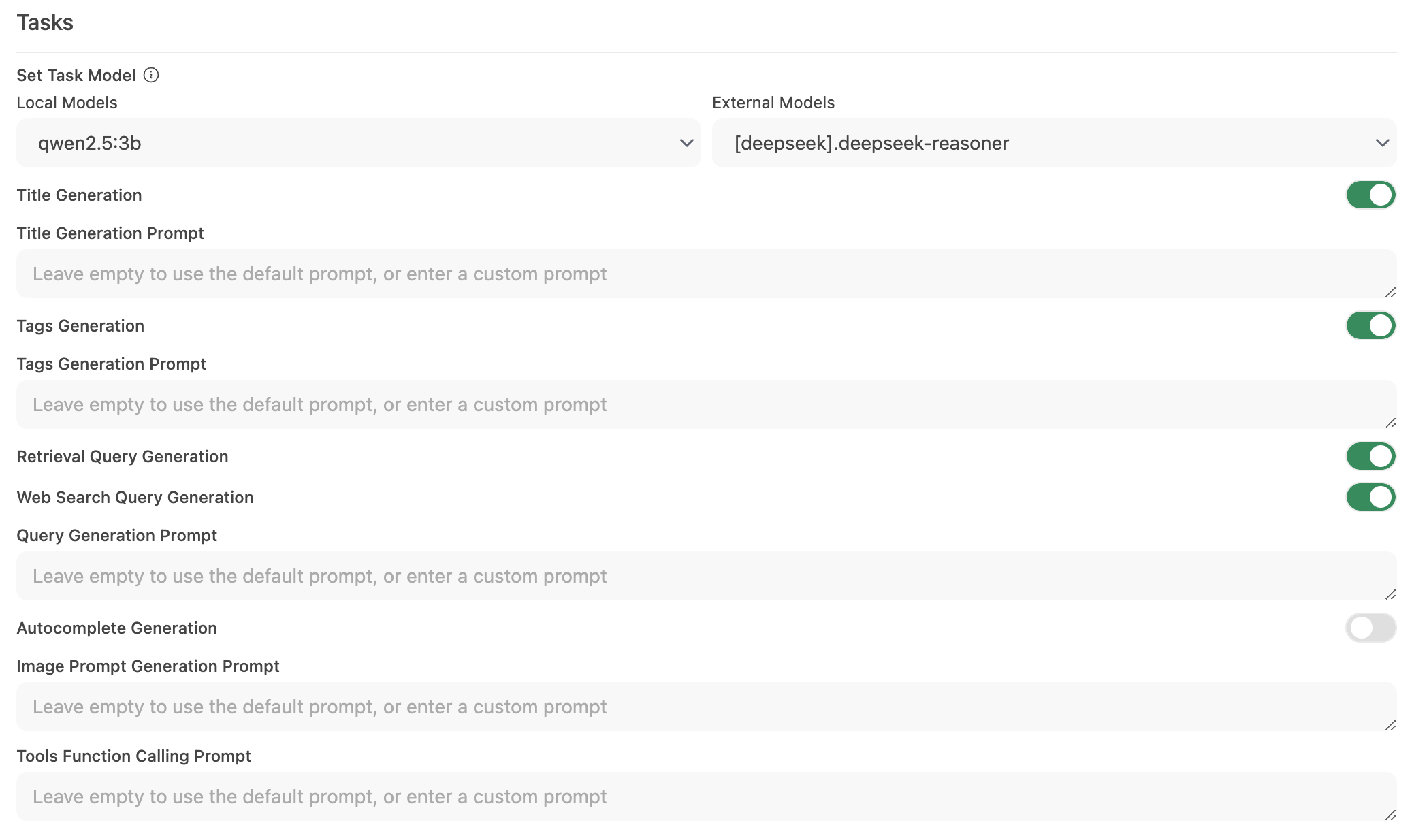
Step 2: Configure the Task Model
-
Go to Interface > Set Task Model.
-
Choose one of the following options based on your needs:
-
Lightweight Local Model (Recommended)
- Select a compact model such as Llama 3.2 3B or Qwen2.5 3B.
- These models offer rapid responses while consuming minimal system resources.
-
Hosted API Endpoint (For Maximum Speed)
- Connect to a hosted API service to handle task processing.
- This can be very cheap. For example, OpenRouter offers Llama and Qwen models at less than 1.5 cents per million input tokens.
OpenRouter Recommendation
When using OpenRouter, we highly recommend configuring the Model IDs (Allowlist) in the connection settings. Importing thousands of models can clutter your selector and degrade admin panel performance.
-
Disable Unnecessary Automation
- If certain automated features are not required, disable them to reduce extraneous background calls—especially features like autocomplete.
-
Step 3: Save Your Changes and Test
- Save the new configuration.
- Interact with your chat interface and observe the responsiveness.
- If necessary, adjust by further disabling unused automation features or experimenting with different task models.
🚀 Recommended Setup for Local Models
| Optimization Strategy | Benefit | Recommended For |
|---|---|---|
| Lightweight Local Model | Minimizes resource usage | Systems with limited hardware |
| Hosted API Endpoint | Offers the fastest response times | Users with reliable internet/API access |
| Disable Automation Features | Maximizes performance by reducing load | Those focused on core chat functionality |
Implementing these recommendations can greatly improve the responsiveness of Open-WebUI while allowing your local models to efficiently handle chat interactions.
⚙️ Environment Variables for Performance
You can also configure performance-related settings via environment variables. Add these to your Docker Compose file or .env file.
Many of these settings can also be configured directly in the Admin Panel > Settings interface. Environment variables are useful for initial deployment configuration or when managing settings across multiple instances.
Task Model Configuration
Set a dedicated lightweight model for background tasks:
# For Ollama models
TASK_MODEL=llama3.2:3b
# For OpenAI-compatible endpoints
TASK_MODEL_EXTERNAL=gpt-4o-mini
Disable Unnecessary Features
# Disable automatic title generation
ENABLE_TITLE_GENERATION=False
# Disable follow-up question suggestions
ENABLE_FOLLOW_UP_GENERATION=False
# Disable autocomplete suggestions (triggers on every keystroke - high impact!)
ENABLE_AUTOCOMPLETE_GENERATION=False
# Disable automatic tag generation
ENABLE_TAGS_GENERATION=False
# Disable search query generation for RAG (if not using web search)
ENABLE_SEARCH_QUERY_GENERATION=False
# Disable retrieval query generation
ENABLE_RETRIEVAL_QUERY_GENERATION=False
Enable Caching and Optimization
# Cache model list responses (seconds) - reduces API calls
MODELS_CACHE_TTL=300
# Cache LLM-generated search queries - eliminates duplicate LLM calls when both web search and RAG are active
ENABLE_QUERIES_CACHE=True
# Convert base64 images to file URLs - reduces response size and database strain
ENABLE_CHAT_RESPONSE_BASE64_IMAGE_URL_CONVERSION=True
# Batch streaming tokens to reduce CPU load (recommended: 5-10 for high concurrency)
CHAT_RESPONSE_STREAM_DELTA_CHUNK_SIZE=5
# Enable gzip compression for HTTP responses (enabled by default)
ENABLE_COMPRESSION_MIDDLEWARE=True
Database and Persistence
# Disable real-time chat saving for better performance (trades off data persistence)
ENABLE_REALTIME_CHAT_SAVE=False
Network Timeouts
# Increase timeout for slow models (default: 300 seconds)
AIOHTTP_CLIENT_TIMEOUT=300
# Faster timeout for model list fetching (default: 10 seconds)
AIOHTTP_CLIENT_TIMEOUT_MODEL_LIST=5
RAG Performance
# Enable parallel embedding for faster document processing (requires sufficient resources)
RAG_EMBEDDING_BATCH_SIZE=100
High Concurrency Settings
For larger instances with many concurrent users:
# Increase thread pool size (default is 40)
THREAD_POOL_SIZE=500
For a complete list of environment variables, see the Environment Variable Configuration documentation.
💡 Additional Tips
- Monitor System Resources: Use your operating system’s tools (such as Activity Monitor on macOS or Task Manager on Windows) to keep an eye on resource usage.
- Reduce Parallel Model Calls: Limiting background automation prevents simultaneous requests from overwhelming your LLM.
- Experiment with Configurations: Test different lightweight models or hosted endpoints to find the optimal balance between speed and functionality.
- Stay Updated: Regular updates to Open-WebUI often include performance improvements and bug fixes, so keep your software current.
Related Guides
- Reduce RAM Usage - For memory-constrained environments like Raspberry Pi
- SQLite Database Overview - Database schema, encryption, and advanced configuration
- Environment Variable Configuration - Complete list of all configuration options
By applying these configuration changes, you'll support a more responsive and efficient Open-WebUI experience, allowing your local LLM to focus on delivering high-quality chat interactions without unnecessary delays.